정형 데이터 - ORM, 정규식
09 Jul 2019 | 데이터빅데이터 청년인재 Day 7
목차
ORM 소개
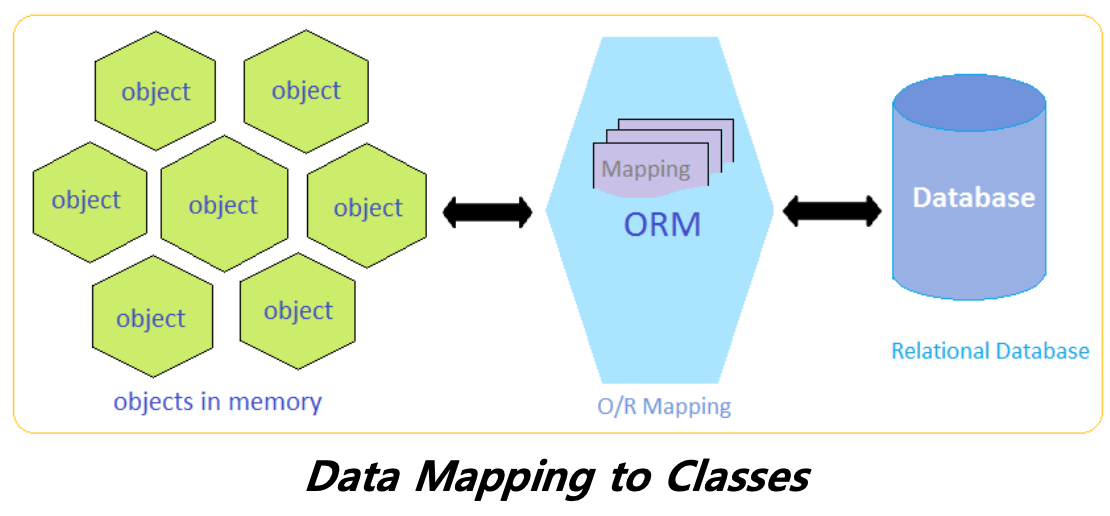
ORM (Object Relational Mapping)이란
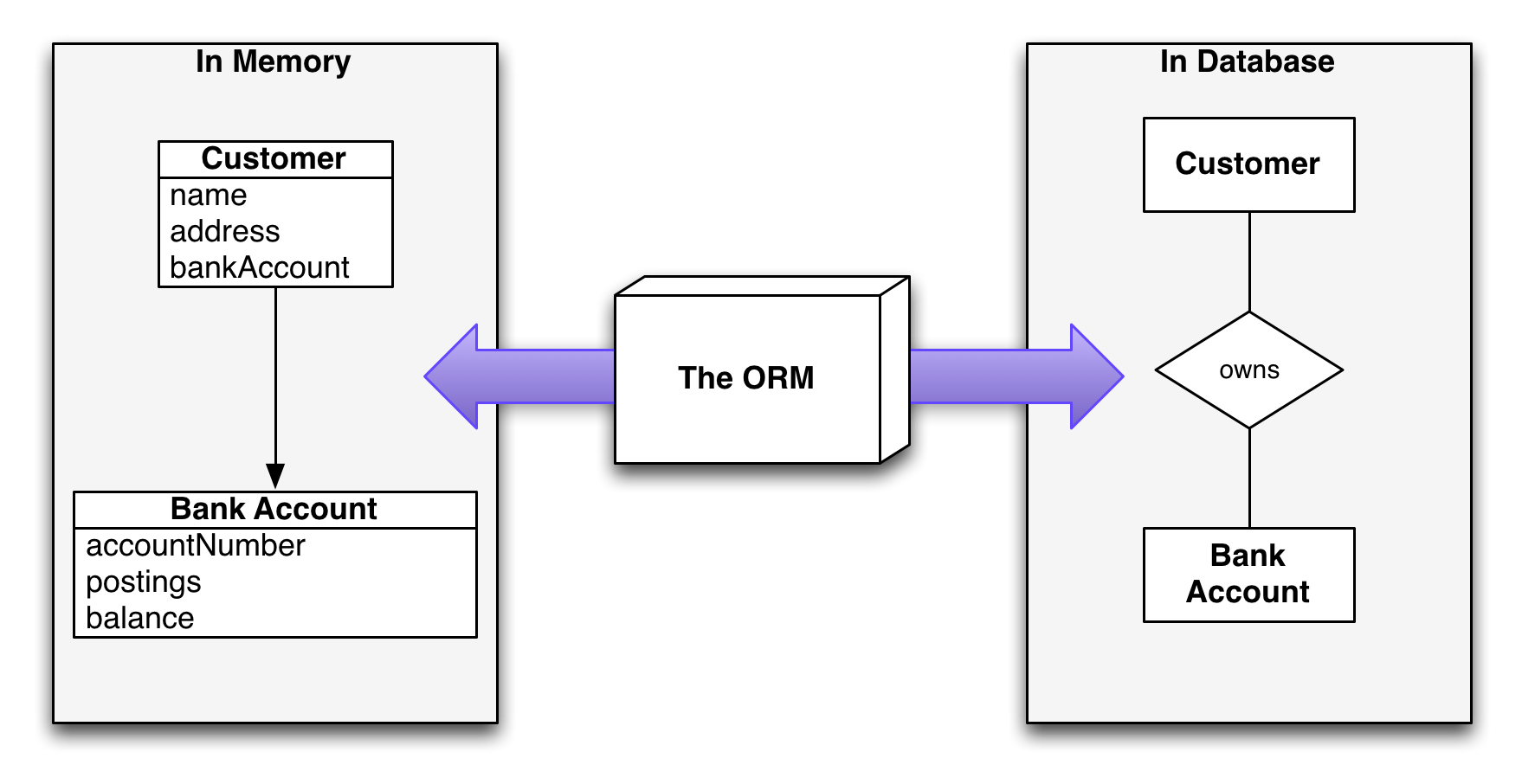
- ORM은 객체-관계 매핑을 의미한다. stands Object Relational Mapping
- 객체 지향 프로그래밍 언어를 사용하여 호환되지 않는 type 시스템 간에 데이터들을 변환하기 위한 프로그래밍 기술이다.
- 메모리에서의 클래스(객체 지향 프로그래밍)와 관계형 데이터베이스의 테이블은 서로 일치하지 않으므로 ORM을 통해 불일치를 해결한다
왜 ORM을 사용해야하는가
- 객체 모델과 관계형 데이터베이스 간의 불일치
- RDBMS는 데이터를 표 형식으로 나타낸다.
- 객체지향언어는 데이터를 객체의 상호 연결된 그래프로 나타낸다. (클래스)
- ORM은 단순한 반복적인 데이터베이스 쿼리를 다루는 것으로부터 프로그래머를 자유롭게 한다.
- 데이터베이스를 비즈니스 객체에 자동으로 매핑 한다.
- 프로퍼티의 값을 변경하는 것만으로 데이터베이스의 값을 바꿀 수 있다.
- 프로그래머들은 비즈니스 문제에 더 많은 관심을 가지고 데이터 저장은 줄인다.
- 매핑 프로세스는 데이터베이스에 도달하기 전에 데이터 검증 및 보안을 지원할 수 있다.
-
ORM은 데이터베이스 위에 캐싱 계층을 제공할 수 있다.
- 단점 : 처리 오버 헤드가 잠재적으로 증가
ORM in Python
- ORM을 사용하면 개발자가 SQL 대신 python 코드로 생성, 읽기, 수정 및 삭제 할 수 있다.
- 개발자는 SQL문을 쓰거나 프로시저를 작성하는 대신에 데이터베이스를 사용하여 편한 프로그래밍 언어를 사용할 수 있다.
- ORM을 사용하여 이론적으로 다양한 관계형 데이터베이스 간에 응용 프로그램을 바꿀 수 있다.
- 그렇지만 연습으로는, 실제로 사용되는 것과 동일한 데이터베이스를 로컬에서 개발하는 것이 가장 좋다.
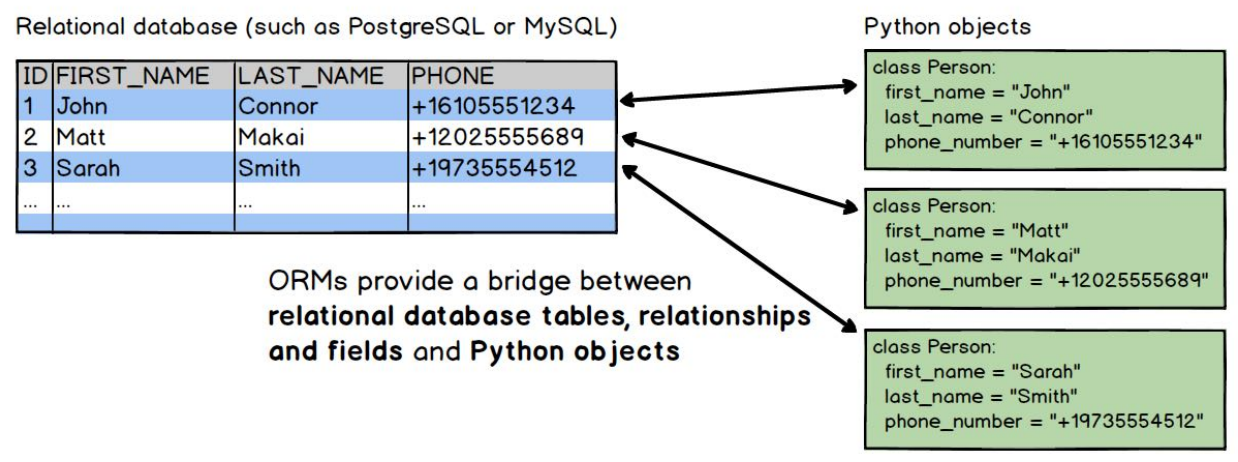
SQLAlchemy
SQLAlchemy란
- SQLAlchemy은 잘 알려진 데이터베이스 툴킷이며 ORM 구현은 파이썬으로 작성되었다.
- SQLAlchemy는 SQL문을 작성할 필요없이 데이터베이스에 독립적인 코드를 작성하고 실행하기 위한 일반화 된 인터페이스를 제공한다.
SQLAlchemy 구조
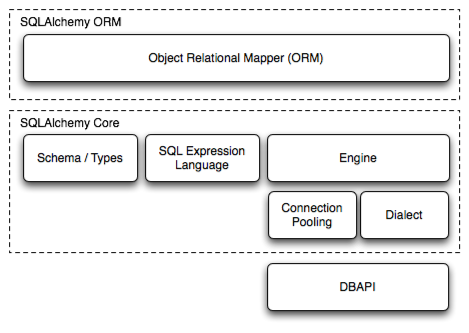
SQLAlchemy core
- 엔진
- SQLAlchemy application의 시작 지점
- 특정 데이터베이스 버스에 연결성을 제공하는 레지스트리(registry)
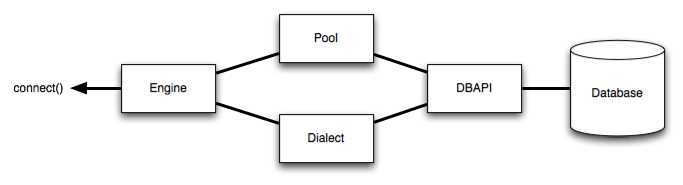
- Dialect
- 다양한 유형의 DBAPI 구현 및 데이터베이스와 통신한다.
- 특정 DBAPI 및 데이터베이스 백엔드의 관점에서 일반 SQL 및 데이터베이스 명령을 해석한다.
- Firebird, Microsoft SQL Server, MySQL, PotsgreSQL, SQLite, Sybase
- Connection Pool
- 빠른 재사용을 위해 메모리에 데이터베이스 연결 모음을 유지한다.
SQLAlchemy 연습
1. Connecting
Create engine
>>> import sqlalchemy
>>> sqlalchemy.__version__
'1.3.1'
>>> from sqlalchemy import create_engine
>>> engine = create_engine("sqlite:///example01.db", echo=True)
>>> #engine = craete_engine("sqlite:///:memory:")
>>> print(engine)
Engine(sqlite:///example01.db)
echo flag를 통해 SQLAlchemy 로그를 볼 수 있다.
create_engine() 의 리턴값은 engine의 객체로 데이터베이스로의 코어 인터페이스를 보여준다.
- Lazy connecting :
create_engine()에 의해 첫번째로 리턴되는엔진은 사실 아직 데이터베이스에 연결하려고 하지 않는다. 이것은 데이터베이스에 대해 처음으로 일을 수행하길 요청할 때 일어난다.
2. Create
from sqlalchemy import Table, Column, Integer, String, MetaData, ForeignKey
metadata = MetaData()
users = Table('users', metadata,
Column('id', Integer, primary_key=True),
Column('name', String),
Column('fullname', String),
)
addresses = Table('addresses', metadata,
Column('id', Integer, primary_key=True),
Column('user_id', None, ForeignKey('users.id')),
Column('email_address', String, nullable=False)
)
metadata.create_all(engine)
# metadata.create_all() 메소드를 통해 데이터베이스 연결의 소스로 엔진에 전달한다.
-
Metadata: 제한된 스키마 생성 명령 집합을 데이터베이스에 내보내는 기능을 포함하는 레지스트리. 테이블 객체와 그들과 관련된 스키마의 collection-
실제 데이터베이스에는 사용자 테이블이 없으므로 MetaData를 사용하여 아직 존재하지 않는 모든 테이블에 대해 CREATE TABLE을 데이터베이스에 발행할 수 있다.
-
테이블 객체는
MetaData.tables딕셔너리에 저장된다.
-
-- log
CREATE TABLE users (
id INTEGER NOT NULL,
name VARCHAR,
fullname VARCHAR,
PRIMARY KEY (id)
)
CREATE TABLE addresses (
id INTEGER NOT NULL,
user_id INTEGER,
email_address VARCHAR NOT NULL,
PRIMARY KEY (id),
FOREIGN KEY(user_id) REFERENCES users (id)
)
3. Insert
# value 값 없음
insert = users.insert()
print(insert)
insert = users.insert().values(name='kim', fullname='Anonymous, Kim')
print(insert)
insert.compile().params
# output
INSERT INTO users (id, name, fullname) VALUES (:id, :name, :fullname)
INSERT INTO users (name, fullname) VALUES (:name, :fullname)
{'name': 'kim', 'fullname': 'Anonymous, Kim'}
insert: INSERT 구문을 나타낸다. 해당TableClause에 대해 insert()를 생성한다.compile: 해당 SQL 구문을 컴파일한다. 리턴 값은 컴파일된 객체이다. 컴파일 된 객체는 params 접근자를 사용하여 바인드 매개 변수 이름 및 값의 딕셔너리를 반환할 수 있다.
4. Executing
conn = engine.connect()
insert.bind = engine
str(insert)
result = conn.execute(insert)
result.inserted_primary_key
# execute의 params 사용
insert = users.insert()
result = conn.execute(insert, name="lee", fullname="Unknown, Lee")
result.inserted_primary_key
#DBAPI의 executemany() 사용
conn.execute(addresses.insert(), [
{"user_id":1, "email_address":"anonymous.kim@test.com"},
{"user_id":2, "email_address":"unknown.lee@test.com"}
])
connection- 래핑된 DBAPI 연결을 위한 고급 기능을 제공
- ClauseElement, Compiled and DefaultGenerator 객체에 대한 문자열 기반 SQL 구문에 대한 실행 지원을 제공
execute- SQL 구문 실행 및 ResultProxy 반환
ResultProxy- 행렬에 대해 더 쉽게 접근 할 수 있도록 DBAPI cursor 객체를 래핑한다.
5. Select
from sqlalchemy.sql import select
query = select([users])
result = conn.execute(query)
for row in result:
print(row)
# output
(1, 'kim', 'Anonymous, Kim')
(2, 'lee', 'Unknown, Lee')
result = conn.execute(select([users.c.name, users.c.fullname]))
for row in result:
print(row)
# output
('kim', 'Anonymous, Kim')
('lee', 'Unknown, Lee')
select- 새로운 Select를 만든다.
- columns, whereclause, from_obj, group_by, order_by, ….
6. ResultProxy
result = conn.execute(query)
row = result.fetchone()
print("id - ", row["id"], ", name - ", row["name"], ", fullname - ", row["fullname"])
row = result.fetchone()
print("id - ", row[0], ", name - ", row[1], ", fullname - ", row[2])
# output
id - 1 , name - kim , fullname - Anonymous, Kim
id - 2 , name - lee , fullname - Unknown, Lee
result = conn.execute(query)
rows = result.fetchall()
for row in rows:
print("id - ", row[0], ", name -", row[1], ", fullname - ", row[2])
result.close()
# output
id - 1 , name - kim , fullname - Anonymous, Kim
id - 2 , name - lee , fullname - Unknown, Lee
fetching(): DB-API cursor.fetchone() 처럼, 한 행만 가져온다.fetchall(): DB-API cursor.fetchall() 처럼, 모든 행을 가져온다.
7. Conjunctions (접속사)
from sqlalchemy import and_, or_, not_
print(users.c.id == addresses.c.user_id)
print(users.c.id == 1)
print((users.c.id == 1).compile().params)
print(or_(users.c.id == addresses.c.user_id, users.c.id == 1))
print(and_(users.c.id == addresses.c.user_id, users.c.id == 1))
print(and_(
or_(
users.c.id == address.c.user_id,
users.c.id ==1
),
addresses.c.email_address.like("a%")
)
)
print((
(users.c.id == addresses.c.user_id) |
(users.c.id == 1)
) & (addresses.c.email_address.like("a%")))
# output
users.id = addresses.user_id
users.id = :id_1
{'id_1': 1}
users.id = addresses.user_id OR users.id = :id_1
users.id = addresses.user_id AND users.id = :id_1
(users.id = addresses.user_id OR users.id = :id_1) AND addresses.email_address LIKE :email_address_1
(users.id = addresses.user_id OR users.id = :id_1) AND addresses.email_address LIKE :email_address_1
8. Selecting
#1
result = conn.execute(select([users]).where(users.c.id == 1))
for row in result:
print(row)
#2
result = conn.execute(select([users, addresses]).where(users.c.id == addresses.c.user_id))
for row in result:
print(row)
#3
result = conn.execute(select([users.c.id, users.c.fullname, addresses.c.email_address]).where(users.c.id == addresses.c.user_id))
for row in result:
print(row)
#4
result = conn.execute(select([users.c.id, users.c.fullname, addresses.c.email_address]).where(users.c.id == addresses.c.user_id).where(addresses.c.email_address.like("Un%")))
for row in result:
print(row)
#output
#1
(1, 'kim', 'Anonymous, Kim')
#2
(1, 'kim', 'Anonymous, Kim', 1, 1, 'anonymous.kim@test.com')
(2, 'lee', 'Unknown, Lee', 2, 2, 'unknown.lee@test.com')
#3
(1, 'Anonymous, Kim', 'anonymous.kim@test.com')
(2, 'Unknown, Lee', 'unknown.lee@test.com')
#4
(2, 'Unknown, Lee', 'unknown.lee@test.com')
9. Join
from sqlalchemy import join
print(users.join(addresses))
print(users.join(addresses, users.c.id == addresses.c.user_id))
# output
users JOIN addresses ON users.id = addresses.user_id
users JOIN addresses ON users.id = addresses.user_id
query = select([users.c.id, users.c.fullname,
addresses.c.email_address]).select_from(users.join(addresses))
result = conn.execute(query).fetchall()
for row in result:
print(row)
# output
(1, 'Anonymous, Kim', 'anonymous.kim@test.com')
(2, 'Unknown, Lee', 'unknown.lee@test.com')
# input
metadata.tables
# output
immutabledict({'users': Table('users', MetaData(bind=None), Column('id', Integer(), table=<users>, primary_key=True, nullable=False), Column('name', String(), table=<users>), Column('fullname', String(), table=<users>), schema=None), 'addresses': Table('addresses', MetaData(bind=None), Column('id', Integer(), table=<addresses>, primary_key=True, nullable=False), Column('user_id', Integer(), ForeignKey('users.id'), table=<addresses>), Column('email_address', String(), table=<addresses>, nullable=False), schema=None)})
# intput
metadata.clear()
metadata.tables
# output
immutabledict({})
SQLAlchemy 실습
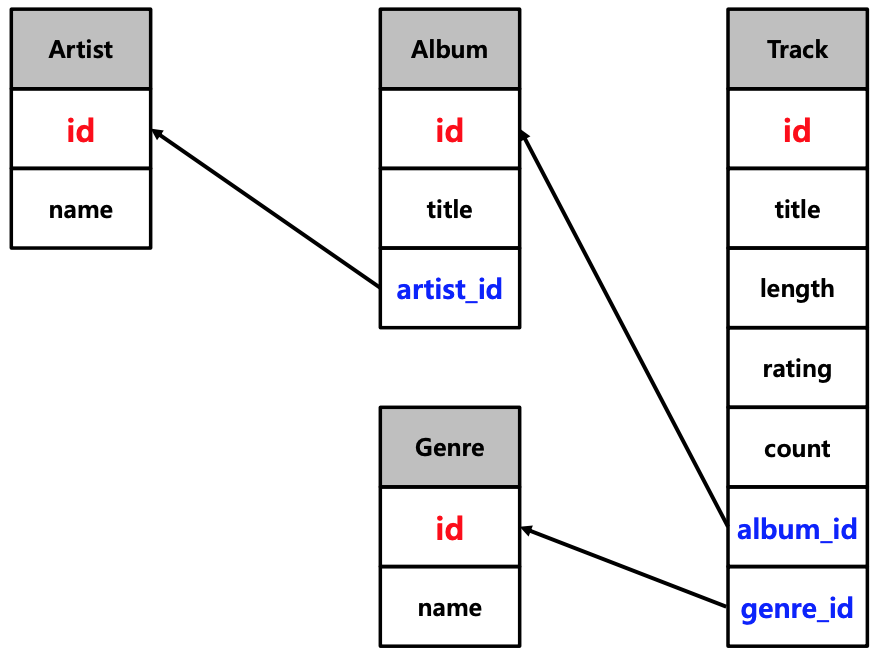
1. engine 생성
import sqlalchemy
sqlalchemy.__version__
from sqlalchemy import create_engine
engine = create_engine("sqlite:///example02.db", echo=True)
print(engine)
# output : Engine(sqlite:///example02.db)
2. Create Table
from sqlalchemy import Table, Column, Integer, String, MetaData, ForeignKey
metadata = MetaData()
artist = Table("Artist", metadata,
Column("id", Integer, primary_key=True),
Column("name", String, nullable=False),
extend_existing=True)
album = Table("Album", metadata,
Column("id", Integer, primary_key=True),
Column("title", String, nullable=False),
Column("artist_id", Integer, ForeignKey("Artist.id")),
extend_existing=True)
genre = Table("Genre", metadata,
Column("id", Integer, primary_key=True),
Column("name", String, nullable=False),
extend_existing=True)
track = Table("Track", metadata,
Column("id", Integer, primary_key=True),
Column("title",String,nullable=False),
Column("length", Integer, nullable=False),
Column("rating", Integer, nullable=False),
Column("count", Integer, nullable=False),
Column("album_id", Integer,ForeignKey("Album.id")),
Column("genre_id", Integer,ForeignKey("Genre.id")),
extend_existing=True)
metadata.create_all(engine)
-- log
CREATE TABLE "Artist" (
id INTEGER NOT NULL,
name VARCHAR NOT NULL,
PRIMARY KEY (id)
)
CREATE TABLE "Genre" (
id INTEGER NOT NULL,
name VARCHAR NOT NULL,
PRIMARY KEY (id)
)
CREATE TABLE "Album" (
id INTEGER NOT NULL,
title VARCHAR NOT NULL,
artist_id INTEGER,
PRIMARY KEY (id),
FOREIGN KEY(artist_id) REFERENCES "Artist" (id)
)
CREATE TABLE "Track" (
id INTEGER NOT NULL,
title VARCHAR NOT NULL,
length INTEGER NOT NULL,
rating INTEGER NOT NULL,
count INTEGER NOT NULL,
album_id INTEGER,
genre_id INTEGER,
PRIMARY KEY (id),
FOREIGN KEY(album_id) REFERENCES "Album" (id),
FOREIGN KEY(genre_id) REFERENCES "Genre" (id)
)
3. Show tables
tables = metadata.tables
for table in tables:
print(table)
# output
Artist
Album
Genre
Track
# 데이터베이스에 있는 테이블
for table in engine.table_names():
print(table)
# output
Album
Artist
Genre
Track
4. Insert
conn = engine.connect()
conn.execute(artist.insert(), [
{"name":"Led Zepplin"},
{"name":"AC/DC"}
])
conn.execute(album.insert(), [
{"title":"IV" ,"artist_id":1},
{"title":"Who Made Who" ,"artist_id":2}
])
conn.execute(genre.insert(), [
{"name":"Rock"},
{"name":"Metal"}
])
conn.execute(track.insert(),[
{"title":"Black Dog", "rating":5, "length":297, "count":0, "album_id":1, "genre_id":1},
{"title":"Stairway", "rating":5, "length":482, "count":0, "album_id":1, "genre_id":1},
{"title":"About to rock", "rating":5, "length":313, "count":0, "album_id":2, "genre_id":2},
{"title":"Who Made Who", "rating":5, "length":297, "count":0, "album_id":2, "genre_id":2}
])
5. Select
artistResult = conn.execute(artist.select())
for row in artistResult:
print(row)
albumResult = conn.execute(album.select())
for row in albumResult:
print(row)
genreResult = conn.execute(genre.select())
for row in genreResult:
print(row)
trackResult = conn.execute(track.select())
for row in trackResult:
print(row)
(1, 'Led Zepplin')
(2, 'AC/DC')
###
(1, 'IV', 1)
(2, 'Who Made Who', 2)
###
(1, 'Rock')
(2, 'Metal')
###
(1, 'Black Dog', 297, 5, 0, 1, 1)
(2, 'Stairway', 482, 5, 0, 1, 1)
(3, 'About to rock', 313, 5, 0, 2, 2)
(4, 'Who Made Who', 297, 5, 0, 2, 2)
6. Where
from sqlalchemy import and_, or_, not_
trackResult = conn.execute(select([track]).where(and_(track.c.album_id == 1, track.c.genre_id == 1)))
for row in trackResult:
print(row)
# output
(1, 'Black Dog', 297, 5, 0, 1, 1)
(2, 'Stairway', 482, 5, 0, 1, 1)
7. Update
from sqlalchemy import update
conn.execute(track.update().values(genre_id=2).where(track.c.id==2))
conn.execute(track.update().values(genre_id=1).where(track.c.id==3))
trackResult = conn.execute(select([track]).where(and_(track.c.album_id == 1, or_(track.c.genre_id == 1, track.c.genre_id == 2,))))
for row in trackResult:
print(row)
# output
(1, 'Black Dog', 297, 5, 0, 1, 1)
(2, 'Stairway', 482, 5, 0, 1, 2)
8. Join
print(track.join(album))
# output
"Track" JOIN "Album" ON "Album".id = "Track".album_id
result = conn.execute(track.select().select_from(track.join(album)))
for row in result.fetchall():
print(row)
# output
(1, 'Black Dog', 297, 5, 0, 1, 1)
(2, 'Stairway', 482, 5, 0, 1, 2)
(3, 'About to rock', 313, 5, 0, 2, 1)
(4, 'Who Made Who', 297, 5, 0, 2, 2)
result = conn.execute(track.select().select_from(track.join(album)).where(album.c.id==1))
for row in result.fetchall():
print(row)
# output
(1, 'Black Dog', 297, 5, 0, 1, 1)
(2, 'Stairway', 482, 5, 0, 1, 2)
9. Multiple Join
print(track.join(album))
print(track.join(album).join(genre))
print(track.join(album).join(artist))
print(track.join(album).join(genre).join(artist))
-- log
"Track" JOIN "Album" ON "Album".id = "Track".album_id
"Track" JOIN "Album" ON "Album".id = "Track".album_id JOIN "Genre" ON "Genre".id = "Track".genre_id
"Track" JOIN "Album" ON "Album".id = "Track".album_id JOIN "Artist" ON "Artist".id = "Album".artist_id
"Track" JOIN "Album" ON "Album".id = "Track".album_id JOIN "Genre" ON "Genre".id = "Track".genre_id JOIN "Artist" ON "Artist".id = "Album".artist_id
result = conn.execute(select([track.c.title, album.c.title, genre.c.name, artist.c.name]).select_from(track.join(album).join(genre).join(artist)))
for row in result.fetchall():
print(row)
# output
('Black Dog', 'IV', 'Rock', 'Led Zepplin')
('Stairway', 'IV', 'Metal', 'Led Zepplin')
('About to rock', 'Who Made Who', 'Rock', 'AC/DC')
('Who Made Who', 'Who Made Who', 'Metal', 'AC/DC')
result = conn.execute(track.select().select_from(track.join(album)\
.join(genre).join(artist))
.where(
and_(
genre.c.id==1,
artist.c.id==1,
)
)
)
for row in result.fetchall():
print(row)
# output
(1, 'Black Dog', 297, 5, 0, 1, 1)
10. Open/Close
from sqlalchemy import create_engine, MetaDate
engine = create_engine("sqlite:///real_db.db")
conn = engine.connect()
metadata = MetaData(bind=engine, reflect=True)
metadata.reflect(bind=engine)
for row in metadata.tables:
print(row)
tables = metadata.tables
for table in tables:
print(table)
# album
track = metadata.tables["Track"]
for row in conn.execute(track.select()).fetchall():
print(row)
conn.close()
metadata.clear()
SQLAlchemy ORM
1. Declare
from sqlalchemy.ext.declarative import declarative_base
base = declarative_base() # 객체 생성
ORM을 사용할 때 사용할 데이터베이스 테이블을 설명하고 해당 테이블에 매핑되는 자체 클래스를 정의해야한다. SQLAlchemy 에서는 이 두 작업은 일반적으로 Declarative 을 통해 수행할 수 있다.
우리의 어플리케이션은 일반적으로 가져온 모듈 데이터베이스의 인스턴스를 하나만 갖는다. 이러한 기본 클래스는 declarative_base() 함수를 통해 만들 수 있다. declarative_base() 상속해야하는 모든 매핑된 클래스들로부터 새로운 베이스 클래스를 반환한다.
또한, 매핑 클래스 내에서 데이터베이스의 column을 나타내는 column 클래스, 각 컬럼의 데이터타입을 나타내는 Integer, String 클래스를 불러와야한다.
2. Create
# 아직은 메모리에
class User(base):
__tablename__ = "users"
id = Column(Integer, primary_key=True)
name = Column(String)
fullname = Column(String)
password = Column("passwd", String)
def __repr__(self):
return "<T'User(name='%s', fullname='%s', password='%s')>"%(self.name, self.fullname, self.password)
- table과 mapper는 __table__과 __mapper__ 어트리뷰트를 통해 접근할 수 있다.
# schema
User.__table__
# create table
base.metadata.create_all(engine)
# create instance
kim = User(name="kim", fullname="anonymous, Kim", password="kimbap heaven")
print(kim)
print(kim.id)
3. Session
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
session = Session()
Ssession:Session은 데이터베이스와의 모든 대화를 설정하고 모든 객체를 나타낸다. ORM 매핑 객체에 대한 지속적인 작업을 관리한다.sessionmaker: 호출 될 때 새로운 Session 객체를 생성한다.sessionmaker class는 일반적으로 최상위 세션 구성을 만드는데 사용된다.
4. Insert
session.add(kim)
-
add: 다음 flush 작업 시 데이터베이스에 유지되는 세션에 객체를 배치한다.add()에 의한 반복적인 호출은 무시한다. -
add_all: 주어진 인스턴스 집합들을 세션에 추가한다.
session.add_all([
User(name="lee", fullname="unknown, Lee", password="123456789a"),
User(name="park", fullname="nobody, Park", password="Parking in Park")
])
- 보류한다. 아직 SQL이 실행되지 않았으며 객체가 데이터베이스의 행으로 표현되지 않았다.
5. Update
kim.password = "password"
session.dirty
session.is_modified(kim)
dirtydirty로 간주되는 모든 지속적인 인스턴스의 집합- 인스턴스는 수정되었지만 삭제되지 않은 경우 더러운 것으로 간주된다.
is_modified: 지정된 인스턴스에 로컬로 수정된 어트리뷰트가 있으면 True로 만환한다.
6. Commit
commit- 보류중인 변경 사항을 flush(반영?)하고 현재 트랜잭션을 커밋한다.
- 진행중인 트랜잭션이 없으면 이 메소드는
InvalidRequestError를 발생시킨다.
7. Select
for row in session.query(User):
print(type(row))
print(row.id, row.name, row.fullname, row.password)
query: ORM 수준의 SQL 생성 객체. ORM에 의해 발생된 모든 SELECT 구문의 원본이다.
for row in session.query(User.id, User.fullname).filter(User.name == "lee"):
print(type(row))
print(row.id, row.fullname)
filter- SQL 식을 사용하여, 해당 쿼리의 복사본에 지정딘 필터링 조건을 적용한다.
- 매핑된 클래스에 클래스 수준의 어트리뷰트와 함께 일반 파이썬 연산자를 사용할 수 있다.
for row in session.query(User.id, User.fullname).filter_by(name = "lee"):
print(type(row))
print(row.id, row.fullname)
filter_by: 키워드 표현식을 사용하여, 해당 쿼리의 복사본에 주어진 필터링 기준을 적용한다.
Regular Expression
RE란
- __검색 패턴__을 나타내기 위한 특별한 문자
- 주로 탐색하고, 바꾸고, 텍스트를 파싱하는 목적으로 사용한다.
왜 RE를 사용하는가
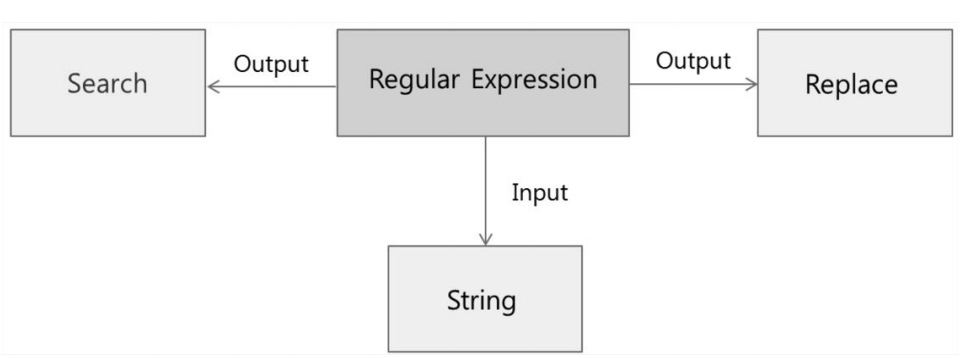
- 엄청나게 많은 텍스트 데이터를 처리하는데 가장 속도가 빠르다.
- 일반적으로 이 패턴은 문자열 검색 알고리즘에 의해 “찾아내기” 또는 “찾아서 바꾸기”에 사용된다.
Comments