정규표현식 (Regular Expression)
14 Jul 2019 | 데이터정규표현식
Meta characters
- 메타 문자 : 원래 그 문자가 가진 뜻이 아닌 __특별한 용도__로 사용하는 문자
. ^ $ * + ? { } [ ] \ | ( )
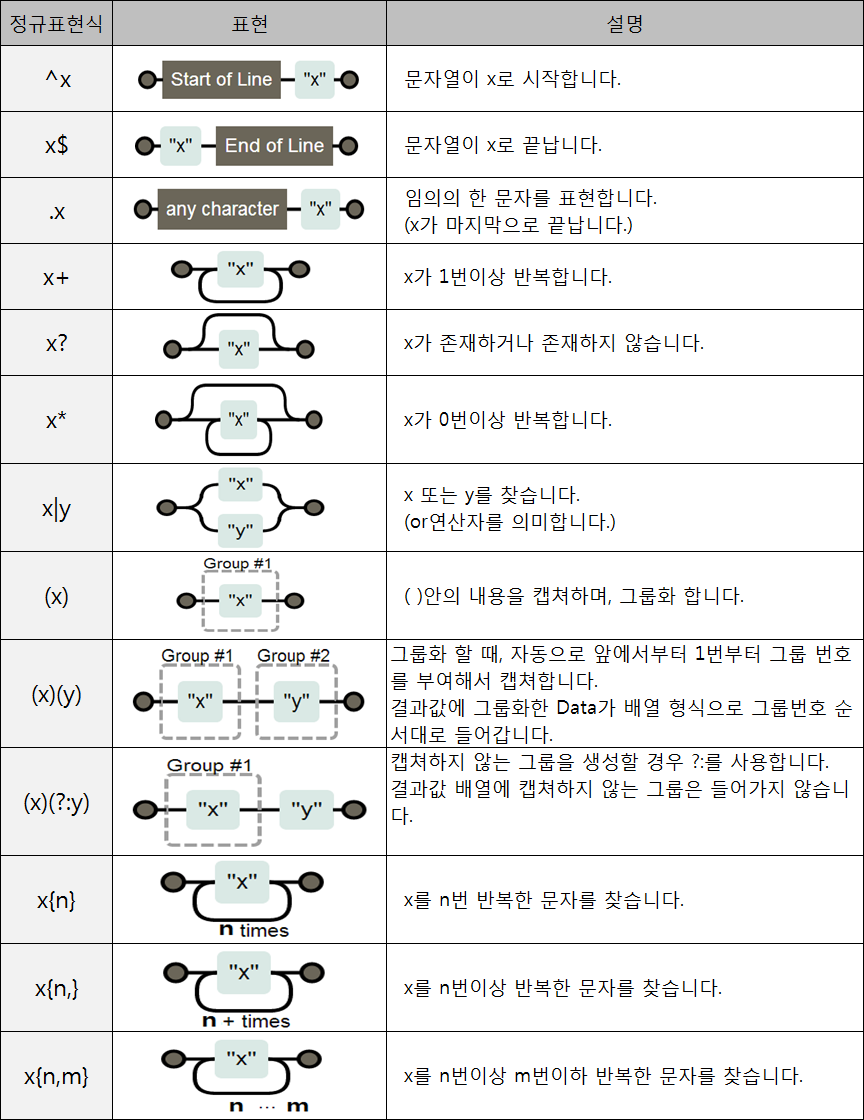
.: Dot(.) 메타문자는 줄바꿈 문자인\n를 제외한 모든 문자와 매치된다.- a.b == a+모든문자+b
- ex) aab, a0b,
abc a[.]b== a+Dot(.)문자+b (a.b,a0b)
*: ab*c == a+b(0번 이상 반복)+c- ex) ac, abc, abbbbbbc,
+: ab+c == a+b(1번 이상 반복)+c- ex) abc, abbbbbc,
ac
- ex) abc, abbbbbc,
{m}: 반드시 m번 반복- ex) ca{2}t →
cat, caat
- ex) ca{2}t →
{m, n}: m~n번 반복- ex) ca{2,5}t →
cat, caat, caaaaat
- ex) ca{2,5}t →
?: ab?c == a+b(1개 있거나 없거나)+c- ex) ac, abc,
abbbc
- ex) ac, abc,
Character classes
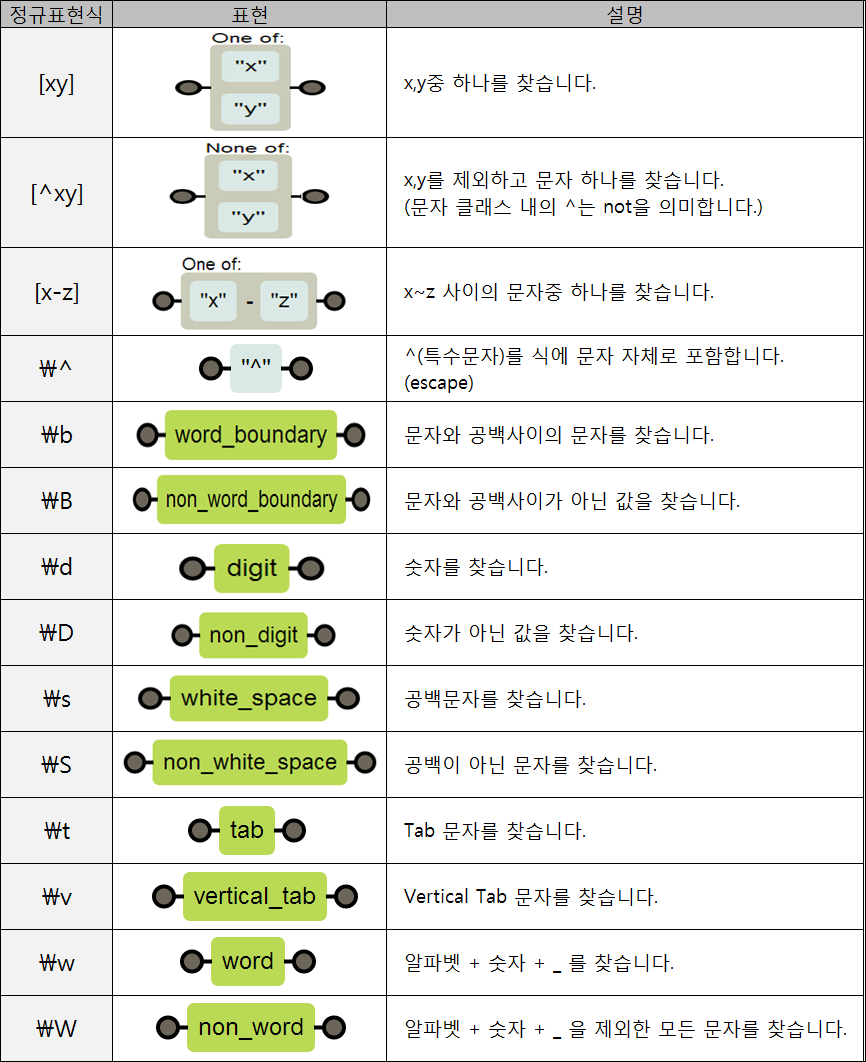
-
[ ]: [ ] 사이의 문자들과 매치 -
\d: 숫자 (==[0-9]) -
\D: 숫자 아닌 것 (==[^0-9]) -
\s: 공백문자 (==[ \t\n\r\f\v]) -
\S: 공백문자 아닌 것 (==[^ \t\n\r\f\v]) -
\w: 모든 알파벳+숫자+_ (==[a-zA-Z0-9_]) -
\W: 알파벳+숫자+_ 아닌 것 ==[^a-zA-Z0-9_])
정규식 사용
1) 정규 표현식 컴파일
파이썬에서 정규 표현식을 지원하기 위해 re 모듈 제공한다.
>>> import re
>>> p = re.compile('ab*')
re.compile을 사용하여 ab* 를 컴파일하고 결과로 돌려주는 객체 p(컴파일 된 패턴 객체)를 사용하여 이후의 작업을 수행한다.
2) 백슬래시 문제
정규표현식은 백슬래시(\)를 사용하여 특정 패턴을 나타날 때 문제가 나타날 수 있다.
| Characters | Stage |
|---|---|
\section |
매치될 문자열 |
\\section |
re.compile() 에 대해 이스케이프 처리 된 백슬래시 |
"\\\section" |
문자열 리터럴에 대해 이스케이프 처리 된 백슬래시 |
그래서 문제를 해결하기 위해 정규식 문자열 앞에 r 을 붙여준다.
| Regular String | Raw String |
|---|---|
"ab*" |
r"ab*" |
"\\\\section" |
r"\\section" |
"\\w+\\s+\\1" |
r"\w+\s+\1" |
더 자세한 설명은 여기
3) 정규식을 이용한 문자열 검색
(1) match()
문자열의 __처음__부터 정규식과 매치되는지 조사. 정규식과 매치되면 match 객체를 돌려주고, 매치되지 않을 때는 None을 리턴한다.
>>> import re
>>> p = re.compile('[a-z]+')
>>> p.match("")
>>> print(p.match(""))
None
>>> print(p.match("a"))
<re.Match object; span=(0, 1), match='a'>
>>> print(p.match("bcafdfz"))
<re.Match object; span=(0, 7), match='bcafdfz'>
>>> print(p.match("0azd1234dfc"))
None
>>> print(p.match("afadfads0"))
<re.Match object; span=(0, 8), match='afadfads'>
>>> print(p.match("123123aa"))
None
>>> print(p.match("aaa"))
<re.Match object; span=(0, 3), match='aaa'>
(2) search()
문자열 __전체__를 검색하여 정규식과 매치되는지 조사. 정규식과 매치되면 match 객체를 돌려주고, 매치되지 않을 때는 None을 리턴한다.
>>> print(p.search("123"))
None
>>> print(p.search("aaa"))
<re.Match object; span=(0, 3), match='aaa'>
>>> print(p.search('123123aa'))
<re.Match object; span=(6, 8), match='aa'>
match와 달리 문자열 전체를 검사하기 때문에 123adb 에 대하여 match는 None을 리턴한 반면 serach는 aa 문자열을 리턴한다.
(3) findall()
정규식과 매치되는 __모든 문자열__을 리스트로 돌려줌
>>> print(p.findall("aaa"))
['aaa']
>>> print(p.findall("213124aa"))
['aa']
>>> print(p.findall("adfad123adf"))
['adfad', 'adf']
(4) finditer()
정규식과 매치되는 모든 문자열을 반복 가능한 객체로 돌려줌
>>> print(p.finditer("123adfada123"))
<callable_iterator object at 0x10a4f0128>
4) match 객체의 메소드
(1) group()
매치된 문자열을 돌려줌
>>> x = p.match("aifojadf")
>>> x
<re.Match object; span=(0, 8), match='aifojadf'>
>>> x.group()
'aifojadf'
(2) start(), end()
매치된 문자열의 시작 위치와 끝 위치를 돌려줌
>>> x.start(), x.end()
(0, 8)
(3) span()
매치된 문자열의 (시작, 끝)에 해당하는 튜플을 돌려줌
>>> x.span()
(0, 8)
>>> x = p.match('123adf')
>>> x.group()
AttributeError
# 'NoneType' object has no attribute 'group'
>>> x = p.match('adf123')
>>> x.group()
'adf'
>>> x.start(), x.end()
(0, 3)
>>> x.span()
(0, 3)
5) 컴파일 플래그
(1) ASCII, A
(2) DOTALL, S
. 이 줄바꿈 문자를 포함하여 모든 문자와 매치할 수 있도록 한다.
>>> import re
>>> p = re.compile('a.b')
>>> m = p.match('a\nb')
>>> print(m)
None
>>> p = re.compile('a.b', re.DOTALL)
>>> m = p.match('a\nb')
>>> print(m)
<_sre.SRE_Match object at 0x01FCF3D8>
(3) IGNORESCASE, I
대소문자 관계없이 매치할 수 있도록 한다.
>>> p = re.compile('[a-z]', re.I)
>>> p.match('python')
<_sre.SRE_Match object at 0x01FCFA30>
>>> p.match('Python')
<_sre.SRE_Match object at 0x01FCFA68>
>>> p.match('PYTHON')
<_sre.SRE_Match object at 0x01FCF9F8>
(4) LOCALE, L
(5) MULTILINE, M
여러줄과 매치할 수 있도록 한다. (^ 와 $ 메타문자의 사용과 관계가 있는 옵션)
>>> import re
>>> p = re.compile("^python\s\w+", re.MULTILINE)
>>> data = """python one
life is too short
python two
you need python
python three"""
>>> print(p.findall(data))
['python one', 'python two', 'python three']
(6) VERBOSE, X
verbose 모드를 사용할 수 있도록 한다. (정규식을 보기 편하게 만들어주고 주석 등을 사용할 수 있게 된다)
charref = re.compile(r'&[#](0[0-7]+|[0-9]+|x[0-9a-fA-F]+);')
# 이거를
charref = re.compile(r"""
&[#] # Start of a numeric entity reference
(
0[0-7]+ # Octal form
| [0-9]+ # Decimal form
| x[0-9a-fA-F]+ # Hexadecimal form
)
; # Trailing semicolon
""", re.VERBOSE)
# 이런식으로 쓸 수 있게 해줌
다른 기능들
1) 그룹핑
| group(인덱스) | 설명 |
|---|---|
| group(0) | 매치된 전체 문자열 |
| group(1) | 첫 번째 그룹에 해당되는 문자열 |
| group(2) | 두 번째 그룹에 해당되는 문자열 |
| group(n) | n 번째 그룹에 해당되는 문자열 |
>>> m = re.match(r"(\w+) (\w)+", "Isaac Newton, physicist")
>>> print(m.group(0))
Isaac Newton
>>> print(m.group(1))
Isaac
>>> print(m.group(2))
n
>>> print(m.group(1,2))
('Isaac', 'n')
>>> p = re.compile(r"(\w+) (\w)+")
>>> m = p.search("Isaac Newton, physicist")
>>> print(m.group())
Isaac Newton
2) Non-capturing and Named Groups
(1) Non-caputring group
단독 그룹을 검색 결과 문자열에 포함시키고 싶지 않은 경우 : (?:…)
>>> m = re.match("([abc])+", "abc")
>>> m.groups()
('c',)
>>> m = re.match("(?:[abc])+", "abc")
>>> m.groups()
()
(2) Named Groups
숫자로 인덱싱 하는 대신에 그룹 이름을 지정 : (?P<name>…)
- name : 그룹의 이름
>>> p = re.compile(r'(?P<word>\b\w+\b)')
>>> m = p.search( '(((( Lots of punctuation )))' )
>>> m.group('word')
'Lots'
>>> m.group(1)
'Lots'
3) 전방 탐색 (Lookahead Assertion)
>>> p = re.compile(".+:")
>>> m = p.search("http://google.com")
>>> print(m.group())
http:
http:에서 :를 제외하고 출력하려면?
(1) 긍정형 전방 탐색
긍정형 전방 탐색((?=…)) - … 에 해당되는 정규식과 매치되어야 하며 조건이 통과되어도 문자열을 소비하지 않는다
>>> p = re.compile(".+(?=:)")
>>> m = p.search("http://google.com")
>>> print(m.group())
http
(2) 부정형 전방 탐색
부정형 전방 탐색 ((?!…)) - … 에 해당되는 정규식과 매치되지 않아야 하며 조건이 통과되어도 문자열이 소비되지 않는다.
문자열 수정하기
1) 문자열 분할
(1) split()
문자열을 목록으로 분할하고 정규식이 일치하는 모든 부분을 분할
>>> p = re.compile(r'\W+')
>>> p.split('This is a test, short and sweet, of split().')
['This', 'is', 'a', 'test', 'short', 'and', 'sweet', 'of', 'split', '']
# 분할 횟수 제한
>>> p.split('This is a test, short and sweet, of split().', 3)
['This', 'is', 'a', 'test, short and sweet, of split().']
\W 는 알파벳과 숫자를 제외한 모든 문자열이고 \W+는 이 문자열들이 1번 이상 반복되는 것이다. 그러니까 알파벳+숫자로 이루어진 문자열들을 제외한 부분들을 분할
>>> p = re.compile(r'\W+')
>>> p2 = re.compile(r'(\W+)')
>>> p.split('This... is a test.')
['This', 'is', 'a', 'test', '']
>>> p2.split('This... is a test.')
['This', '... ', 'is', ' ', 'a', ' ', 'test', '.', '']
2) 검색 및 바꾸기
(1) sub()
sub(바꿀 문자열, 대상 문자열, 바꾸기 횟수)
>>> p = re.compile('(blue|white|red)')
>>> p.sub('colour', 'blue socks and red shoes')
'colour socks and colour shoes'
# 원하는만큼만 바꾸고 싶을 때
>>> p.sub('colour', 'blue socks and red shoes', count=1)
'colour socks and red shoes'
(2) subn()
sub() 랑 동일한 기능인데 반환 결과를 튜플로 돌려준다. 튜플의 첫번째 요소는 변경된 문자열, 두번째 요소는 바꾸기가 발생한 횟수
>>> p = re.compile('(blue|white|red)')
>>> p.subn( 'colour', 'blue socks and red shoes')
('colour socks and colour shoes', 2)
common problems
1) 문자열 메소드 사용
re모듈을 사용하기 전에 문자열 메소드로 해결할 수 있으면 메소드를 사용하자
2) match() vs search()
match() 는 문자열의 앞에서부터 정규식을 찾고 search() 는 문자열 전체에서 매치할 정규식을 찾는다. 즉 match() 는 0부터 찾기 때문에 문자열이 0부터 시작하지 않으면 match() 는 이를 알려주지 않는다.
>>> print(re.match('super', 'superstition').span())
(0, 5)
>>> print(re.match('super', 'insuperable'))
None
반면에 search() 는 문자열을 검색하여 정규식을 찾으면 알려준다.
>>> print(re.search('super', 'superstition').span())
(0, 5)
>>> print(re.search('super', 'insuperable').span())
(2, 7)
match()를 계속 사용하고 그저 정규식 앞에 .* 를 추가하고 싶겠지만 쓰기 않고 search() 를 사용하자. .* 를 추가하면 최적화가 되지 않기 때문에 (문자열 끝까지 스캔 한 다음 역추적 해서 나머지 정규식에 대한 일치 항목을 찾는다) search() 를 사용하자
3) Greedy vs Non-Greedy
a* 처럼 정규식을 반복할때, 가능한 많은 패턴들을 소비하려고 한다.
>>> s = '<html><head><title>Title</title>'
>>> len(s)
32
>>> print(re.match('<.*>', s).span())
(0, 32)
>>> print(re.match('<.*>', s).group())
<html><head><title>Title</title>
<.*> 정규식의 결과로 <html> 문자열을 원했지만, 최대한의 문자열인 <html><head><title>Title</title> 을 소비했다.
이를 해결하기 위해서 *?, +?, ??, {m, n}? 과 같이 ? 문자열을 사용하여 탐욕을 줄일 수 있다.
>>> print(re.match('<.*?>', s).group())
<html>
4) re.VERBOSE 사용
pat = re.compile(r"\s*(?P<header>[^:]+)\s*:(?P<value>.*?)\s*$")
# 보다는
pat = re.compile(r"""
\s* # Skip leading whitespace
(?P<header>[^:]+) # Header name
\s* : # Whitespace, and a colon
(?P<value>.*?) # The header's value -- *? used to
# lose the following trailing whitespace
\s*$ # Trailing whitespace to end-of-line
""", re.VERBOSE)
# 이게 훨씬 읽기 쉽다!
re.VERBOSE 를 사용하면 정규식 공백도 무쉬도고 주석을 사용할 수 있을 뿐더러 “”” “”” 를 사용하여 더 정교하게 형식화 할 수 있다. 그러니까 re.VERBOSE 를 사용하자~~
Comments