Python (3) - 함수형 기법
03 Jul 2019 | python빅데이터 청년인재 Day 3
목차
- 함수형 프로그래밍
- 함수형 기법의 장점
- 이터레이터 (iterator)
- 제너레이터 (generator)
- 반복식 (comprehension)
- First Class Function
- LEGB Rule
- 기타 및 정리
함수형 프로그래밍
- 함수형 기법 : 함수를 이용하여 프로그래밍을 하는 방식
- 함수의 세트로 문제를 분할한다.
- 함수의 입력으로부터 동작해서 출력을 만든다.
- 함수를 이용하게 되면 side effect를 줄일 수 있다.
- def로 묶여 있는 것이 모듈화
# 절차적 프로그래밍
>>> a = input()
>>> a = int(a)
3
>>> import time
>>> def x(a=time.time):
>>> return a
>>> time.time()
562419842.0954182
# 1
- 멀티 패러다임 : 파이썬은 순수한 함수형 패러다임이 아니다. 객체지향언어를 기반으로 함수형 패러다임까지 지원하는 것이기 때문에 함수형 패러다임에 집착할 필요가 없고 필요한 부분만 가져다 사용하면 된다.
함수형 기법의 장점
1) 형식적 증명 가능성
프로그램이 올바른지 증명하기 위해서는 항상 참인 입력 데이터를 넣어야한다. 즉 중간에 값이 바뀌면 안되기 때문에 자료 형태가 mutable 형태이면 불가능하고 __immutable만 가능__하다.
2) 모듈성
프로그램을 작은 조각(함수)으로 분해할 수 있다. 작은 조각들을 잘 만들면 읽거나 오류 수정에 더 용이하고 다른 함수와 함성 시킬 수 있다.
3) 결합성
함수형 프로그램을 만들 때, 다양한 입력과 출력으로 여러가지 함수를 작성할 수 있다.
4) 디버깅과 테스트 용이성
함수형 방식 프로그램은 일반적으로 함수가 작고 분명하게 명시되기 때문에 디버깅이 단순화된다. 또한 각 함수는 잠재적으로 단위 테스트의 대상이라 테스트가 더 쉽다.
이터레이터 (Iterator)
이터레이터는 순환 가능한 객체로 전체 중에서 한 번에 한 개씩만 반환한다. 이터레이터는 next() 혹은 __next__ 메소드를 통해 객체의 다음 요소를 반환한다.
for X in Y 에서 Y는 이터레이터 혹은 iter() 가 이터레이터를 생성할 수 있는 객체여야 한다.
list_iterator
>>> a = [1, 2, 3]
>>> b = iter(a)
>>> type(b)
list_iterator
>>> next(b)
1
>>> next(b)
2
>>> next(b)
3
>>> next(b)
StopIteration
>>> b
<list_iterator at 0x10e41aba8>
>>> list(b)
[]
StopIteration : Iterator에 의해 생성된 항목이 더이상 없다는 것을 알려주기 위해, 내장함수 next() 나 이터레이터의 __next__ 메소드가 일으킨다.

>>> import dis
>>> def iterator_exam():
>>> for i in [1, 2, 3]:
>>> print(i)
>>> dis.dis(iterator_exam)
# dis : 어셈블리어로 바꿔준다
# for문 돌 때 이터레이터가 쓰인다
- output :
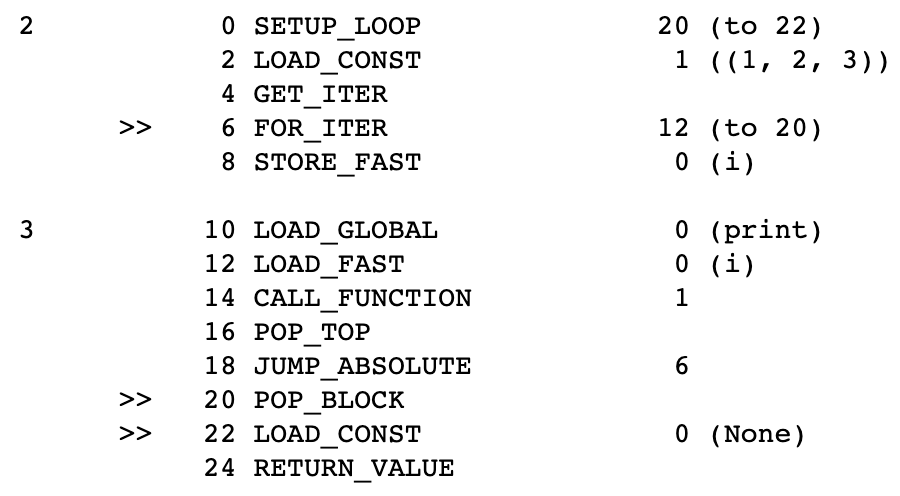
set_iterator
>>> a = {1, 2, 3}
>>> b = iter(a)
>>> type(b)
set_iterator
>>> next(b)
1
>>> next(b)
2
>>> next(b)
3
>>> next(b)
StopIteration
str_iterator
>>> a = 'legolas'
>>> b = iter(a)
>>> b # output :
<str_iterator at 0x10e582588>
>>> next(b)
'l'
>>> list(b)
['e', 'g', 'o', 'l', 'a', 's']
>>> type(b)
str_iterator
-
파이썬에서 이터레이터의 장점 : Lazy
Lazy : 실행되기 전까지는 메모리 상에 안 올리고 실행되면 하나씩 메모리에 올려서 실행한다. 즉, 위의 예에서 next 할 때 하나씩 메모리에 올라간다. 이러한 방법은 속도가 느린데 파이썬에서는 Lazy의 속도를 올리기 위해 내부적으로 최적화가 되어있다. 따라서, python의 lazy 기법은 속도도 빠르다.
-
next는 pop하고 비슷하나 다르다. pop은 뒤에서부터 뽑는다면 next는 앞에서부터 뽑는다.
- 내부적으로 이터레이터로 바꾼다.
- iterator 지원하는 데이터형 : 리스트, 튜플, 문자열, 딕셔너리, 집합
>>> set(dir(Iterator)) - set(dir(Iterable))
{'\__next__'}
즉 이터레이터에는 next가 있고 이터러블에는 없다. 따라서 이터러블 쓸 곳에서 이터레이터를 써도 된다.
제너레이터 (Generator)
제너레이터는 이터레이터를 작성하는 작업을 단순화 하는 특별한 클래스의 함수.
>>> def generator_exam():
>>> yield 1
>>> yield 2
>>> yield 3
>>> x = generator_exam()
>>> type(x)
generator
>>> next(x)
1
>>> next(x)
2
>>> next(x)
3
>>> next(x)
StopIteration
- StopIteration : try except와 같이 쓰면 좋을 듯
yield 키워드를 포함하는 함수는 제너레이터 함수이다. yield와 return의 차이점은 yield에 도달하면 제너레이터의 실행 상태가 일시중단되고 지역변수가 보존된다. 제너레이터 또한 next() 혹은 __next__를 사용할 수 있으며 lazy한 장점이 있다.
# 아래처럼도 사용 가능하다
>>> def generator_exam():
>>> yield from [1, 2, 3, 4]
>>> x = generator_exam()
>>> next(x)
1
>>> next(x)
2
>>> next(x)
3
>>> next(x)
4
>>> next(x)
StopIteration
sum((x for x in range(1,11)))
sum(x for x in range(1,11)) # 위의 식을 현재 식처럼 축약 가능하다
반복식 (Comprehension)
초기화하는데 유용하다. for문보다 속도가 더 빠르다.
1) 리스트 (List)
>>> [x for x in range(10)]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> [x+1 for x in range(10)]
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> [x/3 for x in range(10)]
[0.0, 0.3333333333333333, 0.6666666666666666, … , 3.0 ]
>>> [str(x) for x in range(10)]
['0', '1', '2', '3,' '4', '5', '6', '7', '8', '9']
>>> [0 for x in range(10)] # 이처럼 초기화 하는데 유용하다
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
2) 집합 (Set)
>>> {x for x in range(10)}
{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
3) 딕셔너리 (Dictonary)
>>> {x:1 for x in range(10)}
{0:1, 1:1, 2:1, 3:1, 4:1, 5:1, 6;1, 7:1, 8:1, 9:1}
4) 튜플? (tuple)
튜플(immutable)은 제너레이터이기 때문에 next를 사용하면 된다.
First Class Funtion
파이썬에서 함수는 값이기 때문에 할당문에서 오른쪽에 쓸 수 있다.
- example 1
>>> a = print
>>> a('legolas')
legolas
>>> a.__name__
'print' #(실제로는 print지만 a로도 쓸 수 있다)
>>> printf = print
>>> printf("hello world") :
hello world
- example 2
>>> sum = 0
>>> sum + 1 :
1
>>> del sum
>>> del sum
NameError #(함수 sum만 남았기 때문에 name 'sum'은 정의되지 않음)
- example 3 : 아래와 같은 예시에서는 더 이상 sum 함수를 사용하지 못한다.
>>> sum = 0
>>> for i in range(1,101):
>>> sum+=i
>>> sum
5050
- example 4
>>> a = [str, int, float]
>>> a[0]
str
>>> a[0](2)
'2'
>>> def a(x):
>>> print(x())
>>> a(print)
None
파이썬의 LEGB rule
변수 찾는 순서도 L → E → G → B이다.
1) L (LOCAL)
함수 내의 범위
>>> def y():
>>> x=1
>>> print(x)
>>> y()
1
>>> def y():
>>> z=1
>>> print(z)
>>> z
NameError # 캡슐화
>>> y.z = 3
>>> y()
1
>>> y.z
3
즉 z와 y.z는 다르다.
2) E (Enclosing function rule)
중첩 함수(nested function / 함수 안에 함수) 라면 그 밖에 있는 함수 범위
>>> def y():
>>> def z():
>>> return 1
>>> return z()
>>> y()()
1
>>> def y():
>>> print('legolas')
>>> return y
>>> y()
legolas
>>> y()()
legolas
legolas
closure
>>> def y(x):
>>> def z():
>>> return 1
>>> return z
>>> y(3)()
1
def y(x):
>>> def z():
>>> return x+1
>>> return z
>>> y(3)()
4
>>> def y(x):
>>> def z(n):
>>> return x+n
>>> return z
>>> two_add = y(2)
>>> two_add(3)
3
>>> two_add = y(4)
>>> two_add(3)
7
#lambda 사용
>>> def y(x):
>>> return lambda n:n+x
>>> two_add = y(2)
>>> two_add(4)
>>> a=1
>>> def x():
a=3
def y():
return a
return y()
3
- 첫 번째 인자를 무엇으로 받느냐에 따라 두번째 인자를 전체적으로 바꿀 수 있다.
3) G (Global)
함수 밖을 일컫는 범위
>>> x = 1
>>> def y():
>>> print(x)
>>> y()
1
>>> x = 1 # 접근 할 수 있지만 변경은 불가
>>> def y():
>>> x=x+1
>>> print(x)
>>> y()
UnBoundLocalError #할당 전에 참조되기 때문에 에러
>>> x = 1
>>> def y():
>>> global x
>>> x=x+1
>>> print(x)
>>> y()
2
>>> y()
3
>>> a=1
>>> def x():
return a
>>> x()
1
>>> a = 1
>>> def x():
global a
a=2
return a
>>> x()
2
>>> a=1
>>> def x():
def y():
return a
return y()
>>> x()
1
- global 선언 시 함수 안밖의 객체가 싱크된다. 즉 함수 내부에서 함수 외부의 것을 바꿀 수 없지만 global을 통해 싱크가 되어 바꿀 수 있다. 하지만 global을 사용하는 것은 안 좋다. 내가 생각하는 값이 있는데 global 객체가 있는 함수를 실행함으로써 값이 바뀔 수 있기 때문이다. 일종의 C언어의 goto 같은 존재. (python consenting adults)
4) B (Built-in)
내장 영역
5) nonlocal
nonlocal 문은 나열된 식별자들이 전역을 제외하고 가장 가까이서 둘러싸는 스코프에서 이미 연결된 변수를 가르키도록 만든다. nonlocal 문에 나열된 이름들은, global 문에 나열된 것들과는 달리, 둘러싼 스코프에서 이미 존재하는 연결들을 가르켜야한다. 또한, nonlocal 문에 나열되는 이름들은 지역 스코프에 이미 존재하는 연결들과 겹치지 않아야한다.
>>> a = 1
>>> def x():
>>> return a
>>> a
1
>>> a = 1
>>> def x():
>>> global a
>>> a = 2
>>> return a
>>> x()
2
>>> a=1
>>> def x():
>>> def y():
>>> return a
>>> return y()
>>> x()
1
>>> a=1
>>> def x():
>>> a=3
>>> def y():
>>> return a
>>> return y()
>>> x()
3
>>> a=1
>>> def x():
>>> a=3
>>> def y():
>>> a=a+1 #
>>> return a
>>> return y()
>>> x()
UnboundLocalError

>>> a=1
>>> def x():
>>> a=3
>>> def y():
>>> global a
>>> a=a+1
>>> return a
>>> return y()
>>> x()
2
>>> a=1
>>> def x():
>>> a=3
>>> def y():
>>> nonlocal a
>>> a=a+1
>>> return a
>>> return y()
>>> x()
4
>>> a=1
>>> def x():
>>> b=3
>>> def y():
>>> return b
>>> return y()
>>> x()
3
>>> a=1
>>> def x():
>>> b=3
>>> def y():
>>> return b
>>> print(b+1)
>>> return y()
>>> x()
4 # 출력값
3 # 리턴값
>>> a=1
>>> def x():
>>> def y():
>>> print(c)
>>> c=3
>>> return b
>>> print(b+1)
>>> return y()
>>> x()
NameError

>>> a=1
>>> def x():
>>> def y():
>>> print(c)
>>> c=3
>>> return 1
>>> return y()
>>> x()
UnbounLocalError
UnboundLocalError : 함수/변수를 찾아보니 있는데 아직 메모리에 할당이 안 됐을 때 발생
>>> print(yy)
>>> yy=3
NameError
>>> a=1
>>> def x():
def y():
return 1
print(b)
return y()
>>> x()
NameError # b가 없다
>>> a=1
>>> def x():
def y():
return 1
print(b)
b=1
return y()
>>> x()
UnboundLocalError
# local에서 찾는데 있다! 근데 아직 할당이 안 됐으니까 UnboundLocalError 발생
내장함수
1) map
map(function, iterable, …) : iterable 모든 항목에 function을 적용한 후 그 결과를 돌려주는 이터레이터를 돌려준다. 간단히 말해 뒤에 있는 데이터를 앞에 있는 함수에 넣어 데이터 전체를 바꿔준다.
def add_one(x):
return x+1
map(add_one, [1,2,3,4,5])
# 이렇게만 쓰면 아무것도 보이지 않는다.
>>> list(map(add_one, [1,2,3,4,5]))
[2, 3, 4, 5, 6]
# 람다 함수 또한 함수 인자로 넣을 수 있다.
>>> list(map(lambda x:x+1, [1,2,3,4,5]))
[2, 3, 4, 5, 6]
따라서 일일이 for문에 넣는 것보다 위와 같은 방식으로 한번에 바꿔주는 것이 효율적이다.
# 응용
>>> for i in map(lambda x:x+1, [1,2,3,4,5]):
>>> print(i)
2
3
4
5
6
2) filter
filter(function, iterable) : 참을 돌려준다. 조건은 true 혹은 false를 받아내야한다.
>>> tuple(filter(lambda x:x>3, [1,2,3,4,5,6]))
(4, 5, 6)
3) reduce
원래 기본적인 내장함수였는데 functiontool로 들어갔음.
functools.reduce(function, iterable[, initialize]) : 더 이상 내장함수는 아니다. 순차적으로 두 개의 인자로 이루어진 함수를 왼쪽에서 오른쪽으로 적용하며 단일 값으로 줄인다. 속도도 좋아지고 메모리 효율성도 좋아진다.
>>> from functools import reduce
>>> reduce(lambda x,y:x+y, [1,2,3,4,5])
15
# reduction(축소식) : 위의 예에서 x,y가 있으면 x+y를 한다
# [1,2,3,4,5]에서 1,2가 있으면 1+2 => 3
# [3,3,4,5]에서 3,3가 있으면 3+3 => 6
# [6,4,5]에서 6,4가 있으면 6+4 => 10
# [10,5]에서 10+5가 있으면 10+5 => 15
>>> from functools import reduce
>>> add5 = lambda n: n+5
>>> reduce(lambda l, x: l+[add5(x)], range(10), [])
[5, 6, 7, 8, 9, 10, 11, 12, 13, 14]
초기값이 주어질 때
>>> reduce(lambda x,y:x+y, [1,2,3,4], 5)
15
#5를 집어넣으면 이게 초기값이므로 5,1이 처음 인자로 들어가서 5,1 : 6
# 6,2 : 8
# 8,3 : 11
# 11,4 : 15 가 된다
>>> reduce(lambda x,y:x+[y], [1,2,3,4], 5)
TypeError
# x=5, y=1 지원되지 않는 연산자 유형
# 이를 고치기 위해 초기값을 비어있는 연산자로 해주면
# y에 1이 들어가고 결국엔 리스트가 된다.
>>> reduce(lambda x,y:x+[y], [1,2,3,4], [])
[1, 2, 3, 4]
기타 및 정리
1) for 안에 if를 쓰는 두 가지 방식
-
if를 뒤에 쓴다.
>>> [x for x in range(10) if x%2 == 0] [0, 2, 4, 6, 8]for 뒤에 있는 x를 만나면 if 문에 간 후 참이면 x를 실행한다.
-
if를 앞에 쓴다
>>> [x if x%2 == 0 else 3 for x in range(10)] [0, 3, 2, 3, 4, 3, 6, 3, 8, 3] >>> [x if x%2==0 else None for x in range(10)] [0, None, 2, None, 4, None, 6, None, 8, None]if가 참이면 앞의 문장 (if)를 실행하고 거짓이면 뒤의 문장 (else)를 실행한다.
2) 식은 식끼리 붙일 수 있다.
>>> [(x,y) for x in range(1,11) for y in range(10)]
[(1, 0),
(1, 1),
(1, 2),
(1, 3),
(1, 4),
(1, 5),
(1, 6),
(1, 7),
(1, 8),
(1, 9),
(2, 0),
(2, 1),
(2, 2),
(2, 3),
(2, 4),
(2, 5),
...
(10, 9)]
>>> ((x,y) for x in range(1,11) for y in range(10))
<generator object <genexpr> at 0x10e568ed0>
3) for를 쓰지 않는 기법
- 이터레이터 제너레이터
- 실제 for는 있지만 없다고 가정하는 것 : 컴프리헨션(for문을 쓰지 않고 동시에 여러개를 처리하는 기법)
a = [x for x in range(10)]
# vs
temp=[]
for i in range(10);
temp.append(i)
- 재귀
def fibo(n):
if n<2:
return 1
return fibo(n-1) + fibo(n-2) + x
- map, filter, reduce
>>> reduce(lambda x,y:y+x, 'abcde')
edbca
# a b ba
# ba c cba
# cba d dcba
# e dbca edbca
Comments